Pontos-chave
- O robots.txt é um arquivo de texto hospedado na raiz do site que instrui os mecanismos de busca sobre o que podem e o que não podem rastrear.
- Bloquear uma página no robots.txt impede o rastreamento, mas não garante a desindexação. Para remover uma página do índice, o caminho correto é apenas o uso de noindex.
- Um robots.txt bem configurado direciona o crawl budget para as páginas que realmente importam — e protege áreas que não devem ser públicas, como filtros específicos e páginas internas.
- Com a ascensão de bots de IA, o robots.txt ganhou uma nova função: controlar quais modelos de linguagem podem ou não rastrear o seu conteúdo.
Existem arquivos e elementos que ficam nos bastidores de qualquer site e têm impacto direto em como o Googlebot e outros bots interpretam e leem seu conteúdo — mas que poucas pessoas conhecem. O robots.txt é um deles.
Ele não aparece para quem visita o site, não tem design nem texto para as pessoas lerem. É uma instrução técnica, endereçada diretamente aos bots dos mecanismos de busca, dizendo quais páginas podem ser rastreadas e quais devem ser ignoradas.
Ou seja, ele é simples na aparência, mas crítico na prática. Isso porque um robots.txt mal configurado pode bloquear o Google e outros mecanismos de rastrearem páginas importantes, e esse erro passa despercebido com muita facilidade.
A seguir, você vai entender para que serve o robots.txt e por que uma configuração aparentemente pequena pode fazer toda a diferença para a presença do seu site nos mecanismos de busca. Vamos lá?
O que é robots.txt?
O robots.txt é um arquivo de texto hospedado na raiz do seu site, geralmente acessível em seusite.com.br/robots.txt — que segue o padrão chamado Robots Exclusion Protocol. Esse protocolo define como os bots dos mecanismos de busca devem se comportar ao rastrear o site.
Na prática, é uma lista de permissões e bloqueios: você diz quais bots podem acessar o quê. O Google, o Bing e outros mecanismos de busca respeitam essas instruções, assim como bots de IA, embora com algumas particularidades que vamos abordar mais adiante.
Mas é importante deixar claro que o robots.txt funciona como uma instrução, não como uma barreira de segurança. Bots legítimos respeitam as regras, mas bots mal-intencionados podem simplesmente ignorá-las.
Por isso, nunca use o robots.txt para proteger informações sensíveis; para isso, o caminho correto é a autenticação no servidor.
Um arquivo robots.txt básico se parece com isso:

Tradução: todos os bots (*) podem acessar o site inteiro (/), exceto a área de minha conta. E o sitemap.xml está indicado no final para facilitar a descoberta.
Glossário do robots.txt
Ao abrir um arquivo robots.txt pela primeira vez, é comum encontrar termos técnicos que podem parecer confusos. No entanto, eles seguem uma lógica simples: indicar quais bots podem acessar determinadas áreas do site e quais devem ser evitadas.
Antes de entender como criar ou editar esse arquivo, é importante conhecer os principais comandos utilizados. Confira abaixo quais são eles:
| Termo | O que significa |
|---|---|
| User-agent | Define para qual bot a regra se aplica. Use * para todos os bots ou o nome específico de um crawler. |
| Allow | Libera o acesso a um diretório ou URL, mesmo dentro de um bloco com Disallow. |
| Disallow | Bloqueia o acesso a um diretório ou URL específico. |
| Sitemap | Indica ao bot o endereço do sitemap.xml do site. |
| Crawl-delay | Sugere um intervalo (em segundos) entre as requisições do bot — não é suportado pelo Google, mas funciona no Bing. |
| *(asterisco) | Curinga que representa “qualquer coisa”. Em User-agent significa “todos os bots”; em regras de URL, representa qualquer sequência de caracteres. |
| $ (cifrão) | Indica o final de uma URL. Disallow: /*.pdf$ bloqueia apenas URLs que terminam em .pdf. |
Por que o robots.txt importa para o SEO?
Os mecanismos de busca não dedicam recursos ilimitados ao rastreamento de um site. Por isso, um robots.txt bem configurado contribui para que o esforço de rastreamento seja direcionado de maneira mais rápida e eficiente.
O papel do robots.txt no crawl budget
Crawl budget é o esforço que o Googlebot dedica ao rastreamento do seu site. Esse esforço não é ilimitado, especialmente em sites menores ou com pouca autoridade.
Quando o robots.txt está mal configurado e deixa o Google rastrear páginas sem valor, áreas internas, ambientes de desenvolvimento, parâmetros de URL desnecessários, esse esforço vai para o lugar errado. O resultado é que páginas estratégicas podem demorar mais para serem rastreadas e indexadas.
O que acontece quando o robots.txt está mal configurado?
Dois cenários são os mais comuns e os mais problemáticos:
- Bloquear demais: páginas importantes ficam inacessíveis para o Google. Isso pode acontecer por uma regra muito ampla no Disallow, como Disallow: / (que bloqueia tudo), ou por um erro de digitação que afeta mais URLs do que o pretendido.
- Bloquear de menos: ambientes de teste, painéis administrativos ou páginas duplicadas ficam acessíveis para o Googlebot, consumindo crawl budget e potencialmente gerando problemas de conteúdo duplicado no índice.
Como o robots.txt funciona na prática?
Apesar de ser um arquivo simples, o robots.txt utiliza regras específicas para orientar o comportamento dos bots e definir quais áreas do site podem ou não ser rastreadas. Confira a seguir quais são as principais:
Estrutura básica do arquivo
O robots.txt é composto por blocos de instruções. Cada bloco começa com a definição do bot (User-agent) e é seguido pelas regras (Allow ou Disallow):
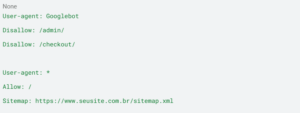
Nesse exemplo, o Googlebot especificamente está bloqueado de acessar /admin/ e /checkout/. Todos os outros bots têm acesso livre ao site.
User-agent: como dar instruções por tipo de bot
O User-agent define para qual bot a regra se aplica. O asterisco (*) significa “todos os bots”. Mas você pode ser mais específico:
- Googlebot – o crawler principal do Google.
- Googlebot-Image – o crawler de imagens do Google.
- Bingbot – o crawler do Bing.
- GPTBot – o crawler do ChatGPT.
- ClaudeBot – o crawler da Anthropic.
Isso permite criar regras diferentes para bots diferentes — algo que ficou especialmente relevante com a chegada dos crawlers de IA.
Allow e Disallow: o que liberar e o que bloquear
- Allow: / – libera o acesso à raiz do site e a tudo dentro dela.
- Disallow: /admin/ – bloqueia o acesso ao diretório /admin/ e tudo dentro dele.
- Disallow: / – bloqueia tudo (muito cuidado com essa instrução).
Uma regra importante: quando há conflito entre Allow e Disallow para a mesma URL, o Google segue a regra mais longa e específica. Se você tem Disallow: /blog/ e Allow: /blog/post-importante, o post específico será liberado, porque a regra de Allow é mais longa, portanto, mais específica.
Como montar um robots.txt do zero?
Agora que você já entende a importância do robots.txt para o rastreamento e o SEO, é hora de ver como esse arquivo é estruturado. Apesar de parecer técnico à primeira vista, ele segue uma lógica simples: identificar os bots que acessarem o site e definir quais áreas podem ou não ser rastreadas.
Veja um passo a passo de como fazer:
O que deve ser bloqueado?
Algumas áreas do site não têm valor para o Google e demais mecanismos, por isso, devem ser bloqueadas:
- Painéis administrativos (/admin/, /wp-admin/).
- Áreas de conta e fluxos internos (/minha-conta/, /checkout/, /carrinho/).
- Parâmetros de URL que geram páginas duplicadas (filtros, sessões, UTMs).
- Páginas de resultados de busca interna.
Importante: ambientes de desenvolvimento, staging e homologação (/dev/, /qa/, /stage/) também não devem ser lidos pelo Google, mas, nesse caso, o ideal é realizar o bloqueio pela meta tag noindex, direto no HTML das páginas do ambiente, não pelo robots.txt.
O motivo é simples: o robots.txt impede o rastreamento, mas não a descoberta. Ou seja, se uma página de desenvolvimento estiver linkada em algum lugar do site ou tiver recebido um link externo, o Google pode encontrá-la normalmente e, como não consegue acessar o conteúdo por causa do bloqueio no robots.txt, também não consegue ler nenhuma instrução presente no HTML da página, incluindo o noindex.
Em outras palavras: robots.txt bloqueado + noindex no HTML = o Google ignora o noindex e a página pode acabar indexada pois o Google não tem permissão de ler a noindex.
Com o noindex aplicado diretamente no HTML e a página liberada no robots.txt, o Google consegue acessar, ler a instrução e respeitar o bloqueio de indexação. Por isso, para ambientes de teste e homologação, o caminho mais seguro é sempre o noindex, sem bloqueio no robots.txt.
O que não deve ser bloqueado?
Alguns erros são mais comuns do que parecem:
- Páginas de produtos, categorias e serviços.
- Posts de blog e conteúdos estratégicos.
- Arquivos CSS e JavaScript – bloquear esses arquivos impede o Google de renderizar as páginas corretamente.
- O próprio sitemap.xml.
É essencial lembrar que as regras do robots.txt se aplicam a qualquer tipo de arquivo, não só a páginas HTML. Imagens, vídeos, PDFs e outros documentos hospedados em diretórios bloqueados também deixam de ser rastreados. Se bloquear uma pasta de imagens, por exemplo, elas param de aparecer no Google Imagens.
Como indicar o sitemap no robots.txt?
Adicionar o endereço do sitemap no robots.txt é uma boa prática, facilita a descoberta por qualquer mecanismo de busca, não só o Google:
![]()
Essa linha vai no final do arquivo, depois das regras de Allow e Disallow.
Como validar o robots.txt?
Depois de gerar o robots.txt, é fundamental validar o arquivo antes da publicação para garantir que as regras estejam funcionando corretamente. Para isso, existem ferramentas que ajudam a verificar se as diretivas foram configuradas corretamente antes e depois da publicação.
Merkle robots.txt Tester (Para validar ANTES de publicar)
Como o Google descontinuou seu antigo Robots.txt Tester do Search Console, ferramentas externas passaram a ser amplamente utilizadas para validar regras e simular o comportamento dos rastreadores.
Soluções como o Merkle Robots.txt Tester ajudam a identificar erros de sintaxe, testar URLs específicas e verificar se páginas importantes estão liberadas para rastreamento antes de enviar o arquivo para produção.
Importante reforçar:
- O arquivo deve sempre estar hospedado na raiz do domínio, acessível em seusite.com.br/robots.txt, e pode ser criado em um editor de texto simples, como o Bloco de Notas, Sublime ou o TextEdit. Editores como o Word adicionam formatação invisível que pode invalidar o arquivo.
- Cada domínio só pode ter um robots.txt; arquivos em subdiretórios são ignorados pelos bots.
Um ponto importante: qualquer alteração no robots.txt deve ser testada antes de ir ao ar. Um erro aqui pode bloquear o rastreamento de páginas inteiras — e o impacto pode demorar dias para aparecer nos relatórios do GSC.
2. Google Search Console (Para validar DEPOIS de publicar)
Depois que o arquivo estiver publicado, utilize a ferramenta de Inspeção de URL do Google Search Console para verificar se páginas específicas estão sendo bloqueadas ou liberadas pelo robots.txt.
Basta inserir a URL desejada, executar o teste da URL publicada e analisar o relatório. O Google informará se o rastreamento está permitido e se existe alguma regra do robots.txt afetando o acesso do Googlebot.
Robots.txt e noindex: qual a diferença e quando usar cada um?
Essa é uma das confusões mais comuns em SEO técnico, e entender a diferença evita erros que passam despercebidos por meses. Confira quais são as principais diferenças entre eles:
Robots.txt bloqueia o rastreamento
Quando uma página está bloqueada no robots.txt, o Googlebot e os bots de outros mecanismos de busca não leem seu código fonte. Isso significa que qualquer instrução presente no HTML — incluindo o noindex — será completamente ignorada.
Se a página já estava indexada antes do bloqueio, ela pode continuar aparecendo nos resultados indefinidamente, já que os bots não têm como ler a instrução de remoção.
Noindex bloqueia a indexação
A tag noindex instrui o Googlebot e demais bots a não incluir a página no índice de busca. Ela é implementada como uma meta tag robots no HTML da página:
![]()
Essa tag fica dentro da meta tag robots, o elemento HTML que concentra as instruções de indexação e rastreamento diretamente no código da página. Além do noindex, ela também aceita outras diretivas, como nofollow, noarchive e combinações entre elas:
![]()
Para que o noindex funcione, a página precisa estar acessível para ser lida — ou seja, liberada no robots.txt. Sem acesso, a instrução não é lida e não tem efeito.
A regra prática é simples:
- Quer que os bots não rastreiem a página? Use o robots.txt.
- Quer que a página não apareça nos resultados de busca? Use o noindex via meta tag robots no HTML e garanta que ela está liberada no robots.txt.
- Nunca use os dois ao mesmo tempo para a mesma página: o bloqueio no robots.txt impede a leitura do noindex, e a página pode continuar indexada mesmo com as duas instruções aplicadas.
Boas práticas e erros comuns no robots.txt
Criar um arquivo robots.txt não é apenas uma questão de adicionar regras de bloqueio. Pequenos ajustes podem influenciar diretamente a forma como os mecanismos de busca rastreiam o site e, em alguns casos, comprometer a indexação de páginas importantes.
Por isso, conhecer as boas práticas e os erros mais comuns é fundamental para manter uma configuração eficiente e segura. Confira a seguir:
Boas práticas:
- Manter o arquivo simples e direto — regras desnecessárias aumentam o risco de erro.
- Sempre testar antes de implementar alterações.
- Indicar o sitemap ao final do arquivo.
- Revisar periodicamente, especialmente após mudanças na estrutura do site.
- Qualquer alteração deve ser alinhada com o time de SEO antes de ir ao ar.
Exemplos práticos por tipo de site:
- E-commerce: bloquear URLs geradas por filtros de pesquisa (cor, tamanho, preço), páginas de carrinho e checkout.
- Blog: bloquear páginas de tags e arquivos de datas.
- Site institucional: bloquear diretórios de administração e páginas de login.
Erros comuns:
- Disallow: / sem querer — bloqueia o site inteiro para todos os bots.
- Bloquear arquivos CSS e JS — impede o Google de renderizar as páginas corretamente.
- Usar robots.txt para desindexar páginas — não funciona como esperado.
- Esquecer de atualizar após mudanças na estrutura do site.
- Criar regras duplicadas ou conflitantes que geram comportamento inesperado.
Robots.txt na era da IA: o que muda com os novos crawlers?
Na prática, a principal mudança é que o robots.txt deixou de influenciar apenas a visibilidade nos buscadores e passou também a ajudar a definir como o conteúdo pode ser acessado e utilizado por plataformas de IA.
A seguir, explicamos mais detalhadamente:
Como bots de IA leem o robots.txt
Assim como o Googlebot, a maioria dos principais crawlers de IA declara respeitar as instruções do robots.txt — cada um com seu próprio User-agent. Os mais comuns são:
- GPTBot – ChatGPT (OpenAI).
- ClaudeBot – Claude (Anthropic).
- PerplexityBot – Perplexity.
- Google-Extended – usado pelo Google para treinar modelos de IA generativa.
Para bloquear um deles especificamente, basta criar uma regra com o User-agent correspondente:

Isso impede o ChatGPT de rastrear o site, sem afetar o Googlebot ou outros crawlers de busca.
Antes de bloquear, é essencial avaliar o impacto dessa decisão. Ao impedir que um bot de IA rastreie o site, o conteúdo deixa de ser rastreado para treinamento ou consulta por aquela ferramenta — mas isso não afeta dados já coletados anteriormente.
Em ferramentas como o ChatGPT e o Perplexity, que cada vez mais são usadas como ponto de partida para pesquisas e decisões de compra, isso significa perder visibilidade em um canal que cresce rapidamente.
O bloqueio pode fazer sentido em alguns contextos, como proteger conteúdo proprietário ou evitar o uso sem atribuição, mas deve ser uma decisão estratégica consciente, não uma configuração padrão.
Leia também: Modo IA do Google — o que é e seu impacto no SEO
Tire suas dúvidas sobre robots.txt
Mesmo entendendo como o robots.txt funciona, é comum surgirem dúvidas sobre sua implementação, indexação, bloqueios e impacto no SEO. A seguir, respondemos a algumas das perguntas mais frequentes sobre esse arquivo e seu papel no rastreamento dos sites. Confira:
1. O robots.txt é obrigatório?
Não. Se o arquivo não existir, os bots simplesmente rastreiam o site inteiro. Em sites com áreas que não devem ser públicas, ambientes de desenvolvimento ou grande volume de páginas sem valor para o Google, o robots.txt é essencial para direcionar o rastreamento corretamente.
2. Com que frequência devo revisar o robots.txt?
Sempre que houver mudanças relevantes na estrutura do site, novos diretórios, novos ambientes, mudanças em áreas que devem ou não ser rastreadas. Uma boa prática é incluir a revisão do robots.txt no checklist de qualquer lançamento ou reestruturação de site.
3. O robots.txt precisa ser implementado em algum lugar específico?
Sim. O arquivo precisa estar hospedado na raiz do domínio, acessível em seusite.com.br/robots.txt. Um robots.txt em qualquer outro caminho não é reconhecido pelos bots e não terá efeito nenhum.
Garanta que seu site seja rastreado da forma certa pelos mecanismos de busca e plataformas de IA!
Um robots.txt bem configurado ajuda a orientar o rastreamento, proteger áreas estratégicas do site e evitar o desperdício de crawl budget. No entanto, para gerar resultados reais, ele precisa fazer parte de uma estratégia técnica de SEO mais ampla.
Na Ecto Digital, analisamos a estrutura do seu site, identificamos oportunidades de otimização e implementamos as melhores práticas de SEO técnico para melhorar a indexação e a visibilidade da sua marca.
Entre em contato com nossa equipe de especialistas e descubra como fortalecer a presença digital do seu negócio.
Leia também: O que é headless CMS e qual a diferença? Saiba quando usá-lo no seu site
Imagem de capa — Fonte: Pvproductions / Magnific.com (2026)