Uma vez trabalhei com um cliente de um nicho bem específico e que seu produto era muito semelhante ao dos concorrentes. Nesse cenário, a disputa por preço era um fator importante para o fechamento de uma venda.
Na época, um dos objetivos dessa loja virtual era melhorar a taxa de conversão. Após algumas análises, verifiquei dificuldades que envolviam o usuário encontrar o produto desejado. Para melhorar isso, recomendei algumas melhorias na interface, como a adição de novos filtros nas páginas de categorias e também em como alguns filtros existentes eram exibidos para o usuário.
Observando as métricas e por meio de uma ferramenta de heatmap (Hotjar), notei que isso ajudou a melhorar a navegação do usuário pelas páginas e fazer com que ele encontrasse o produto que precisava muito mais rápido.
Mas a taxa de conversão não melhorava. Aumentamos o investimento na mídia paga, re-estruturamos a campanha de outra forma, fizemos testes A/B, melhoramos descrição de produtos, melhoramos a árvore de categoria e mesmo assim não víamos melhora.
Em uma dessas análises comecei a notar que o preço para alguns tipos de produtos era muito diferente em relação aos líderes do mercado. Só que eu precisava ter uma visão geral dos produtos e não só de alguns aleatórios para poder defender esse ponto do preço, pois é algo delicado de se abordar.
E é aqui que eu chego no ponto principal deste artigo. Mostrar para você como eu desenvolvi esse estudo de preço dos concorrentes de maneira automatizada e rápida (na época, o custo para contratar uma ferramenta que fazia essa função era elevado e limitada a uma quantidade pequena de produtos). Nos tópicos abaixo eu detalho os caminhos que você deve seguir para fazer algo para o seu cenário.
Além disso, ao final do artigo também disponibilizo uma planilha com exemplo de uma página simples de HTML que construí no laboratório de SEO que temos na Ecto. Por questões éticas, essa foi a forma mais justa de ensinar esse tipo de prática e também para não expor alguma loja publicamente. Com isso, você poderá ver a fórmula funcionar em uma página online (inclusive, você pode tentar extrair outras informações como parte do estudo).
Uma outra observação é que essa ferramenta acaba tendo suas certas limitações em relação à quantidade de requisições. Acredito que algo na faixa de 50 produtos (e até 3 concorrentes) ela deva funcionar bem. Mais do que isso, recomendo utilizar outros métodos de scraping de páginas.
Por exemplo, se você utilizar o Screaming Frog, é possível fazer algo semelhante, pois ele possuí o recurso de extrair informações da página e trabalha com a mesma estrutura de referência que passo nesse artigo. Se você dominar alguma linguagem de programação, saiba que há algumas bibliotecas como Scrapy ou Selenium.
E tenha em mente que você pode precisar fazer alguns ajustes ao longo do tempo, visto que os sites sofrem frequentes melhorias e alterações no código.
Extrair preços de produtos via Google Sheets
Aqui não existe uma fórmula mágica que você consiga extrair essas informações com um XPath único, igual aos exemplos que dei nos artigos de validações técnicas de SEO e no de como extrair URLs de um Sitemap XML, pois cada caso acaba tendo algumas particularidades. Portanto, a minha ideia é mostrar alguns exemplos práticos de lojas online para que você entenda a ideia e possa ajustar em qualquer caso.
Exemplo Loja 1:
O código abaixo peguei de uma loja que comercializam filtros de água e utiliza como base uma grande plataforma de e-commerce:
<div itemtype="http://schema.org/Offer" itemscope="itemscope" itemprop="offers">
<link itemprop="availability" href="http://schema.org/InStock">
<meta content="BRL" itemprop="priceCurrency">
<meta itemprop="price" content="99.00">
</div>
Esse caso acima é o mais fácil para você extrair, pois ele usa dados estruturados de produto no HTML da página, o que facilita a construção do nosso XPath. Para esses casos, seria:
//*[@itemprop='price']/@content
A notícia boa é que o XPath acima pode funcionar em diversas lojas (apesar de eu ter dito que não havia uma fórmula mágica, essa é a que mais se aproxima), pois é um código padrão e está inserido em grande parte das plataformas online. Portanto, aplicando no IMPORTXML teríamos:
=IMPORTXML(url_monitorada;"//*[@itemprop='price']/@content")
Exemplo Loja 2:
Abaixo, outro trecho de código extraído de uma página de produto, agora em uma página que não tinha a marcação de dados estruturados:
<div class="price-box minimalFlag">
<span class="regular-price" id="product-price">
<span class="price">R$479,00</span>
</span>
</div>
Nesse caso, você precisa construir o XPath, pois cada loja acaba tendo um layout diferente e por consequência estruturas de código próprias. Tendo como base o exemplo acima, teríamos o seguinte:
//*[@class='regularprice']/span[@class='price']/text()
Em que o elemento text() informa que eu só quero o texto (dependendo do XPath ele pode retornar código HTML e esse não é o nosso objetivo aqui). Já os elementos anteriores informam uma hierarquia em relação à estrutura do HTML e, de maneira resumida, detalham o caminho para chegar até lá. A ideia aqui não é explicar tanto sobre XPath e caso você queira alguns exemplos, recomendo esse XPath Cheatsheet (lá você vai encontrar exemplos para extrair diversos tipos de elementos numa página).
Planilha de modelo
Para facilitar seus estudos, fiz uma planilha de exemplo:

E como bônus, adicionei um XPath para obter o nome do produto e também fiz uma página bem simples para exibir algumas informações de um produto para fins didáticos em nosso laboratório de SEO:
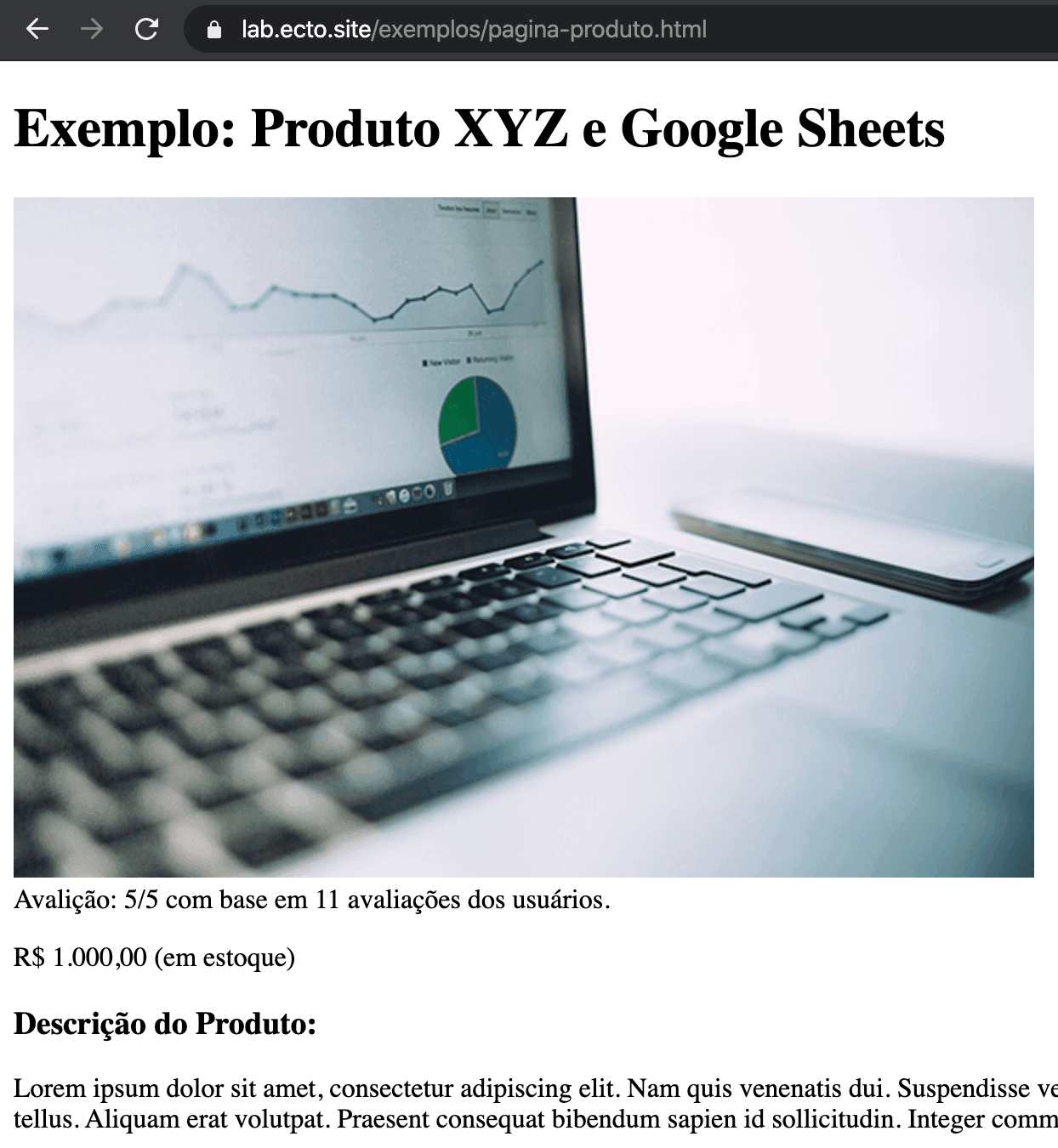
Nessa página há outras informações que você pode treinar extrair informações da página como: a avaliação, descrição e links da página.
Agora, para estruturar a sua planilha de acompanhamento, eu recomendo o seguinte:
- Pegue todas as URLs dos produtos da sua loja que você quer monitorar.
- Faça o mesmo para os seus concorrentes.
- Organize na planilha as URLs equivalentes.
- Dica: use formatação condicional e/ou SUMIFS e/ou COUNTIFS para agrupar as informações (ex: quantos produtos com maior preço, % de produtos acima de X reais, etc.).
Compartilhe um pouco da sua experiência comigo! O que achou desse formato de explicação? Já usou essa fórmula antes? E se tiver alguma dúvida, não deixe de perguntar!